

EN RESUMEN
El RAG inteligencia artificial empresa (Retrieval-Augmented Generation) es la tecnología que conecta modelos de IA generativa —GPT-4, Claude, Gemini— directamente con los documentos, manuales, precios y datos internos de tu negocio. Resultado: respuestas precisas y actualizadas sin riesgo de información inventada. En esta guía te explicamos cómo funciona, cuánto cuesta implementarlo y cómo evitar los errores más comunes en PyMES mexicanas.
El 42% de las empresas a nivel global ya utiliza inteligencia artificial en sus operaciones, según el IBM Global AI Adoption Index 2024. Sin embargo, la queja más frecuente de los directores de PyMES en México es siempre la misma: “la IA no conoce mi negocio”. Responde bien preguntas generales, pero no sabe cuánto cobras por un servicio, qué dice tu contrato de garantía o cómo atiendes las devoluciones. Ahí es exactamente donde entra el RAG inteligencia artificial empresa.
En AddWebTech llevamos 19 años acompañando la transformación digital de empresas mexicanas. Desde 2023 hemos implementado soluciones RAG en logística, e-commerce y servicios profesionales, y los resultados son consistentes: 60-80% de reducción en tiempo de respuesta a clientes y un drástico descenso en los errores por datos desactualizados. Esta guía concentra todo lo que aprendimos en producción.
Contenido de este artículo
- ¿Qué es el RAG inteligencia artificial empresa?
- Cómo funciona el RAG: el viaje de tus datos
- RAG vs. fine-tuning: ¿cuál conviene a tu PyME?
- Casos de uso de RAG en empresas mexicanas
- Cómo implementar RAG inteligencia artificial empresa en 5 pasos
- Costos y plazos para PyMES en México
- Errores frecuentes al implementar RAG
- Preguntas frecuentes sobre RAG
¿Qué es el RAG inteligencia artificial empresa y por qué lo necesitas?
RAG son las siglas de Retrieval-Augmented Generation (Generación Aumentada por Recuperación). En términos prácticos, el RAG inteligencia artificial empresa es una arquitectura que combina dos tecnologías: un motor de búsqueda semántica que recupera los fragmentos más relevantes de tus documentos internos, y un modelo de lenguaje grande (LLM) que genera la respuesta final usando esos fragmentos como contexto inmediato.
Sin RAG, si preguntas a un chatbot “¿cuánto cuesta el servicio X?”, el modelo solo puede responder con lo que aprendió durante su entrenamiento —datos públicos, nada tuyo—. Con RAG, primero busca en tu catálogo de precios actualizado, localiza el precio correcto y redacta una respuesta precisa. Es la diferencia entre un empleado que acaba de entrar y uno que lleva años en tu empresa y conoce cada producto, proceso y política.
Según IBM Research, implementar RAG reduce las “alucinaciones” —respuestas inventadas— de los modelos de IA hasta en un 80%. Para una empresa que usa IA para atender clientes, ese número lo es todo.
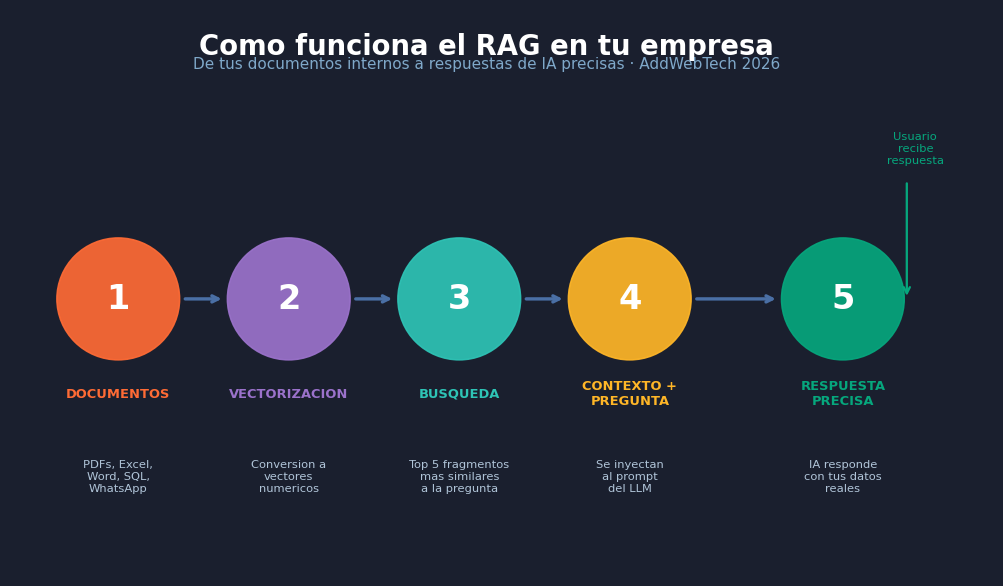
Cómo funciona el RAG: el viaje de tus datos a la IA
El proceso ocurre en dos fases: la indexación (que haces una vez al configurar el sistema) y el ciclo de consulta (que ocurre en milisegundos cada vez que alguien pregunta algo).
Flujo completo de RAG en 4 pasos
PASO 1 · Indexación
Tus documentos (PDFs, manuales, bases de datos) se dividen en fragmentos y se convierten en vectores numéricos almacenados en una base vectorial (Pinecone, pgvector, ChromaDB).
PASO 2 · Consulta
El usuario escribe una pregunta. El sistema la convierte también en vector y busca los fragmentos de tus datos con mayor similitud semántica.
PASO 3 · Recuperación
Se recuperan los 3-10 fragmentos más relevantes de tu base de conocimiento. Estos pasan al modelo de IA como “contexto adicional” junto con la pregunta original.
PASO 4 · Generación
El LLM (GPT-4o, Claude 3.5, Gemini) recibe pregunta + contexto recuperado y genera una respuesta precisa y fundamentada exclusivamente en tus propios datos.
La clave está en los vectores: representaciones matemáticas del “significado” de un texto. Cuando indexas el manual de tu producto, el sistema no guarda las palabras literalmente, sino su esencia semántica. Por eso, si alguien pregunta “¿tienen garantía?” y tu documento habla de “política de devoluciones”, el sistema los conecta aunque las palabras sean distintas. Eso es búsqueda semántica, no búsqueda por palabras clave.
RAG inteligencia artificial empresa vs. fine-tuning: ¿cuál conviene a tu PyME?
Cuando las empresas descubren que la IA no sabe lo suficiente sobre su negocio, surgen dos opciones técnicas: implementar RAG o hacer fine-tuning (reentrenar el modelo con sus datos). La diferencia es crítica en términos de costo, plazo y flexibilidad.
| Criterio | RAG | Fine-tuning |
|---|---|---|
| Costo inicial | Desde $15,000 MXN | Desde $80,000 MXN |
| Tiempo de implementación | 2–6 semanas | 3–6 meses |
| Actualización de datos | Inmediata (subes el doc) | Requiere reentrenar el modelo |
| Precisión sobre datos propios | Muy alta | Alta (pero puede “olvidar”) |
| Volumen de datos necesario | Cualquier cantidad | Miles de ejemplos etiquetados |
| Privacidad de datos | On-premise disponible | Requiere enviar datos al proveedor |
| Recomendado para PyMES MX | SÍ | Solo grandes corporativos |
Para la gran mayoría de las 4.9 millones de PyMES en México (INEGI, 2023), el RAG es la elección correcta: menor inversión, arranque en semanas y posibilidad de actualizar el conocimiento simplemente subiendo nuevos documentos al sistema, sin reentrenar nada.
Casos de uso de RAG en empresas mexicanas
En AddWebTech vemos mayor retorno de inversión en estos escenarios, que aplican a prácticamente cualquier sector:
Atención al cliente 24/7
Chatbot entrenado con tu catálogo, precios, políticas de devolución y preguntas frecuentes. Responde correctamente sin inventar información, a cualquier hora.
Asistente de ventas interno
El agente de ventas consulta “¿qué producto recomiendo para X necesidad?” y recibe sugerencias basadas en tu catálogo real, no en suposiciones de la IA.
Soporte interno para RRHH
Empleados nuevos consultan manuales, reglamentos y procedimientos sin interrumpir a nadie. El asistente cita la fuente exacta del documento.
Análisis de contratos y documentos legales
Sube contratos en PDF y pide al asistente que identifique cláusulas de riesgo, fechas de vencimiento o condiciones específicas en segundos.
E-commerce y logística inteligente
Como en el caso Envifast, conectar inventario e historial de pedidos a un asistente que rastrea envíos y recomienda productos según el historial del cliente.
Reportes ejecutivos automáticos
El asistente consulta tus bases de datos y genera informes en lenguaje natural: “¿cómo fueron las ventas de marzo comparado con febrero?” — respuesta en 3 segundos.
Cómo implementar RAG inteligencia artificial empresa en 5 pasos
Este es el proceso que seguimos en AddWebTech al implementar RAG inteligencia artificial empresa con nuestros clientes, desde el primer diagnóstico hasta la puesta en producción:
Inventario de conocimiento
Mapea qué documentos contienen el conocimiento clave de tu empresa: manuales de producto, listas de precios, FAQs, contratos tipo, políticas internas, correos de soporte frecuentes. Formatos aceptados: PDF, Word, Excel, páginas web, bases de datos SQL, WhatsApp Business exportado.
Elección del LLM y la base vectorial
Para presupuesto ajustado: GPT-4o mini (API de OpenAI) con pgvector en PostgreSQL. Para mayor privacidad o datos sensibles: Llama 3 con ChromaDB en servidor propio. El LLM es el “cerebro”; la base vectorial es la “memoria”.
Chunking e indexación
Los documentos se dividen en fragmentos (“chunks”) de 400–700 tokens, cada uno con su metadata (fuente, fecha, categoría, página). Se indexan como vectores. Esta fase toma 1 a 3 días según el volumen de documentos. Una vez indexado, el sistema está listo para recibir preguntas.
Construcción del pipeline RAG
Se programa la lógica que conecta consulta → búsqueda vectorial → contexto → LLM → respuesta. Frameworks como LangChain o LlamaIndex aceleran este proceso. Normalmente toma 1 a 3 semanas de desarrollo según la complejidad de la integración (CRM, ERP, WhatsApp Business API).
Evaluación y mejora continua
Se mide la calidad de las respuestas con métricas como RAGAS (Retrieval Augmented Generation Assessment Score). Se ajustan el prompt de sistema, el tamaño de los chunks y el número de fragmentos recuperados hasta alcanzar una precisión operativa mayor al 90%.
💡 Tip de AddWebTech
Antes de indexar, limpia y estandariza tus documentos. Un manual con formatos inconsistentes o datos contradictorios producirá respuestas confusas, incluso con la mejor arquitectura RAG del mundo. Dedica el 30% del tiempo del proyecto a preparar los datos: es la inversión que más ROI da en producción. Los clientes que nos entregan documentación ordenada llegan a producción en la mitad del tiempo.
Costos y plazos de un proyecto RAG para PyMES en México
Los costos varían según el volumen de documentos, el LLM elegido y el nivel de integración. Estos son los rangos que manejamos en proyectos reales en 2026:
| Tier | Alcance | Inversión (MXN) | Plazo |
|---|---|---|---|
| Básico | Chatbot RAG sobre FAQ + catálogo (hasta 100 docs, API cloud) | $15,000 – $35,000 | 2–3 semanas |
| Profesional | RAG + integración CRM/ERP + historial de conversación + panel admin | $50,000 – $120,000 | 4–8 semanas |
| Enterprise | RAG multi-agente + pipelines automáticos + modelo LLM on-premise | $150,000+ | 2–4 meses |
Estos son costos de desarrollo. El costo operativo mensual de un RAG básico —llamadas API del LLM + hosting del vector store— suele estar entre $1,500 y $5,000 MXN/mes para 500-2,000 consultas diarias. Comparado con contratar personal de soporte adicional, el ROI se recupera normalmente en 3 a 6 meses.

Errores frecuentes al implementar RAG en tu empresa
Con 19 años acompañando la transformación digital de empresas mexicanas, estos son los errores que más nos encontramos en proyectos de IA que no funcionan como esperado:
Error 1: Subir documentos sin revisar
Precios desactualizados, manuales de versiones antiguas o contratos vencidos contaminan todo el sistema. El RAG devolverá información incorrecta con total confianza, lo que es peor que no tener respuesta.
Error 2: Chunks demasiado grandes o demasiado pequeños
Chunks de 2,000 tokens meten demasiado ruido en cada respuesta; de 100 tokens pierden el contexto necesario. El rango óptimo para documentos empresariales es 400-700 tokens con 10-15% de solapamiento entre chunks consecutivos.
Error 3: No definir el prompt de sistema
Sin instrucciones claras, el LLM mezcla datos de internet con los tuyos, inventa cuando no encuentra respuesta, o cambia de idioma. El prompt de sistema es tu “contrato” con la IA: le dice exactamente qué puede y qué no puede responder.
Error 4: Ignorar seguridad y privacidad de datos
Si indexas contratos o datos de clientes, necesitas cifrado en reposo, control de acceso por rol y cumplimiento con la LFPDPPP. Para datos sensibles, un RAG on-premise con modelo open-source resuelve esto sin exponer información a servidores externos.
Preguntas frecuentes sobre RAG inteligencia artificial
¿Cuánto tiempo tarda implementar RAG en una empresa pequeña?
Un proyecto básico —chatbot sobre FAQ y catálogo de hasta 100 documentos— suele estar en producción en 2 a 3 semanas. El factor más determinante es la calidad y organización de los documentos. Si están bien estructurados y actualizados, el timeline puede reducirse hasta un 40%. Proyectos con integración a CRM o ERP toman entre 4 y 8 semanas.
¿Necesito saber programar para usar RAG en mi empresa?
No. El usuario final interactúa con una interfaz de chat normal, como WhatsApp o un widget en tu sitio web. La programación la hace la agencia o el equipo técnico que implementa el sistema. Una vez configurado, actualizar el conocimiento —subir nuevos documentos— se hace desde un panel de administración sin escribir código.
¿Cuál es la diferencia entre RAG e IA entrenada con mis datos?
El RAG no modifica el modelo de IA: le proporciona información en tiempo real como contexto adicional en cada consulta. El fine-tuning (IA entrenada) modifica el modelo de forma permanente. RAG es más flexible, económico y actualizable al vuelo. El fine-tuning tiene sentido cuando quieres cambiar el tono o estilo del modelo, no solo su base de conocimiento.
¿Qué tipos de documentos puedo usar como fuente en RAG?
Prácticamente cualquier texto estructurado: PDFs, documentos Word, hojas de Excel, páginas web, bases de datos SQL, correos electrónicos, tickets de soporte, transcripciones de llamadas y WhatsApp Business exportado. Cuanto más completo y actualizado sea el corpus de documentos, más preciso y confiable será el asistente.
¿Es seguro enviar los datos de mi empresa a la IA?
Depende de la arquitectura elegida. Con APIs de OpenAI o Anthropic, tus datos pasan por sus servidores (en los planes de API no se usan para reentrenar modelos por defecto). Si manejas datos sensibles —finanzas, datos personales de clientes, información médica— recomendamos un RAG on-premise con modelos open-source como Llama 3 o Mistral corriendo en tu propio servidor, sin exposición externa.
¿Cuánto cuesta mensualmente mantener un RAG activo?
Para un RAG básico con GPT-4o mini y pgvector, el costo operativo mensual está entre $1,500 y $5,000 MXN para un volumen de 500 a 2,000 consultas diarias (incluye llamadas a la API del LLM y hosting del vector store). Con modelos open-source en servidor propio, el costo baja a solo el hosting: entre $800 y $2,500 MXN/mes.
Conclusión: el RAG como ventaja competitiva real para tu empresa
El RAG inteligencia artificial empresa ya no es tecnología de laboratorio ni patrimonio exclusivo de los grandes corporativos. En 2026 es la herramienta más accesible para que cualquier PyME mexicana pase de “usar IA genérica” a “tener una IA que conoce mi negocio de verdad”.
3 puntos clave para llevar:
- RAG = precisión sin reentrenar el modelo: conecta la IA a tus documentos en tiempo real y elimina hasta el 80% de respuestas incorrectas.
- Es mucho más económico que el fine-tuning: desde $15,000 MXN y 2-3 semanas de implementación, con actualización instantánea al subir nuevos documentos.
- La calidad de tus datos lo decide todo: documentos limpios y actualizados producen un asistente confiable; documentos caóticos producen respuestas caóticas.
¿Listo para que la IA aprenda de tu empresa?
En AddWebTech diseñamos e implementamos proyectos RAG desde la estrategia hasta la puesta en producción. 19 años de experiencia en transformación digital de empresas mexicanas.
Cotiza tu proyecto RAG →


